User:Boris Tsirelson/Sandbox2
In probability theory, a standard probability space (called also Lebesgue–Rokhlin probability space or just Lebesgue space; the latter term is ambiguous) is a probability space satisfying certain assumptions introduced by Vladimir Rokhlin in 1940. He showed that the unit interval endowed with the Lebesgue measure has important advantages over general probability spaces, and can be used as a probability space for all practical purposes in probability theory. The theory of standard probability spaces was started by von Neumann in 1932 and shaped by Vladimir Rokhlin in 1940. The dimension of the unit interval is not a concern, which was clear already to Norbert Wiener. He constructed the Wiener process (also called Brownian motion) in the form of a measurable map from the unit interval to the space of continuous functions.
Contents |
[edit] Short history
The theory of standard probability spaces was started by von Neumann in 1932[1] and shaped by Vladimir Rokhlin in 1940.[2] For modernized presentations see (Haezendonck 1973), (de la Rue 1993), (Itô 1984, Sect. 2.4) and (Rudolf 1990, Chapter 2).
Nowadays standard probability spaces may be (and often are) treated in the framework of descriptive set theory, via standard Borel spaces, see for example (Kechris 1995, Sect. 17). This approach, natural for experts in descriptive set theory, is based on the isomorphism theorem for standard Borel spaces (Kechris 1995, Theorem (15.6)) whose proof is very difficult for non-experts in descriptive set theory. The original approach of Rokhlin, based on measure theory, leads to much simpler proofs (since measure theory may neglect null sets, in contrast to descriptive set theory).
Standard probability spaces are used routinely in ergodic theory,[3][4] which cannot be said on probability theory. Some probabilists hold the following opinion: only standard probability spaces are pertinent to probability theory, thus, it is a pity that the standardness is not included into the definition of probability space. Others disagree, however.
Arguments against standardness:
- the definition of standardness is technically demanding;
- the same about the theorems based on that definition;
- it is possible (and natural) to build all the probability theory without the standardness;
- events and random variables are essential, while probability spaces are auxiliary and should not be taken too seriously.
Arguments in favour of standardness:
- conditioning is easy and natural on standard probability spaces, otherwise it becomes obscure;
- the same for measure-preserving transformations between probability spaces, group actions on a probability space, etc.;
- ergodic theory uses standard probability spaces routinely and successfully;
- being unable to eliminate these (auxiliary) probability spaces, we should make them as useful as possible.
[edit] Definition
One of several well-known equivalent definitions of the standardness is given below, after some preparations. All probability spaces are assumed to be complete.
[edit] Isomorphism
An isomorphism between two probability spaces 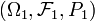 ,
, 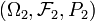 is an invertible map
is an invertible map 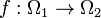 such that
such that 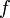 and
and 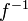 both are (measurable and) measure preserving maps.
both are (measurable and) measure preserving maps.
Two probability spaces are isomorphic, if there exists an isomorphism between them.
[edit] Isomorphism modulo zero
Two probability spaces , are isomorphic 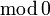 , if there exist null sets
, if there exist null sets 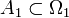 ,
, 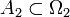 such that the probability spaces
such that the probability spaces 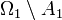 ,
, 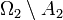 are isomorphic (being endowed naturally with sigma-fields and probability measures).
are isomorphic (being endowed naturally with sigma-fields and probability measures).
[edit] Standard probability space
A probability space is standard, if it is isomorphic to an interval with Lebesgue measure, a finite or countable set of atoms, or a combination (disjoint union) of both.
See (Rokhlin 1962, Sect. 2.4 (p. 20)), (Haezendonck 1973, Proposition 6 (p. 249) and Remark 2 (p. 250)), and (de la Rue 1993, Theorem 4-3). See also (Kechris 1995, Sect. 17.F), and (Itô 1984, especially Sect. 2.4 and Exercise 3.1(v)). In (Petersen 1983, Definition 4.5 on page 16) the measure is assumed finite, not necessarily probabilistic. In (Sinai 1994, Definition 1 on page 16) atoms are not allowed.
[edit] Examples of non-standard probability spaces
[edit] A naive white noise
The space of all functions 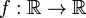 may be thought of as the product
may be thought of as the product 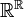 of a continuum of copies of the real line
of a continuum of copies of the real line 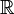 . One may endow with a probability measure, say, the standard normal distribution
. One may endow with a probability measure, say, the standard normal distribution 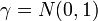 , and treat the space of functions as the product
, and treat the space of functions as the product 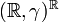 of a continuum of identical probability spaces
of a continuum of identical probability spaces 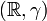 . The product measure
. The product measure 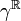 is a probability measure on . Many non-experts are inclined to believe that describes the so-called white noise.
is a probability measure on . Many non-experts are inclined to believe that describes the so-called white noise.
However, it does not. For the white noise, its integral from 0 to 1 should be a random variable distributed N(0, 1). In contrast, the integral (from 0 to 1) of 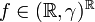 is undefined. Even worse, ƒ fails to be almost surely measurable. Still worse, the probability of ƒ being measurable is undefined. And the worst thing: if X is a random variable distributed (say) uniformly on (0, 1) and independent of ƒ, then ƒ(X) is not a random variable at all! (It lacks measurability.)
is undefined. Even worse, ƒ fails to be almost surely measurable. Still worse, the probability of ƒ being measurable is undefined. And the worst thing: if X is a random variable distributed (say) uniformly on (0, 1) and independent of ƒ, then ƒ(X) is not a random variable at all! (It lacks measurability.)
[edit] A perforated interval
Let 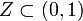 be a set whose inner Lebesgue measure is equal to 0, but outer Lebesgue measure – to 1 (thus,
be a set whose inner Lebesgue measure is equal to 0, but outer Lebesgue measure – to 1 (thus, 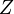 is nonmeasurable to extreme). There exists a probability measure
is nonmeasurable to extreme). There exists a probability measure 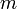 on such that
on such that 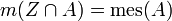 for every Lebesgue measurable
for every Lebesgue measurable 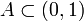 . (Here
. (Here 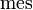 is the Lebesgue measure.) Events and random variables on the probability space
is the Lebesgue measure.) Events and random variables on the probability space 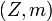 (treated ) are in a natural one-to-one correspondence with events and random variables on the probability space
(treated ) are in a natural one-to-one correspondence with events and random variables on the probability space 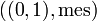 . Many non-experts are inclined to conclude that the probability space is as good as .
. Many non-experts are inclined to conclude that the probability space is as good as .
However, it is not. A random variable 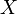 defined by
defined by 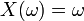 is distributed uniformly on
is distributed uniformly on 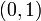 . The conditional measure, given
. The conditional measure, given 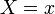 , is just a single atom (at
, is just a single atom (at 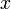 ), provided that is the underlying probability space. However, if is used instead, then the conditional measure does not exist when
), provided that is the underlying probability space. However, if is used instead, then the conditional measure does not exist when 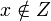 .
.
A perforated circle is constructed similarly. Its events and random variables are the same as on the usual circle. The group of rotations acts on them naturally. However, it fails to act on the perforated circle.
See also (Rudolph 1990, page 17).
[edit] A superfluous measurable set
Let be as in the previous example. Sets of the form  where
where 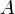 and
and 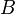 are arbitrary Lebesgue measurable sets, are a σ-algebra
are arbitrary Lebesgue measurable sets, are a σ-algebra 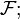 it contains the Lebesgue σ-algebra and
it contains the Lebesgue σ-algebra and 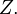 The formula
The formula
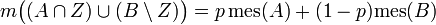
gives the general form of a probability measure on 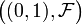 that extends the Lebesgue measure; here
that extends the Lebesgue measure; here ![\textstyle p \in [0,1]](../../w/images/math/5/5/d/55d174349e6dbd9d7b67ec707e7c095c.png) is a parameter. To be specific, we choose
is a parameter. To be specific, we choose 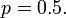 Many non-experts are inclined to believe that such an extension of the Lebesgue measure is at least harmless.
Many non-experts are inclined to believe that such an extension of the Lebesgue measure is at least harmless.
However, it is the perforated interval in disguise. The map
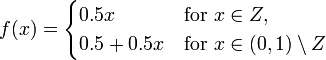
is an isomorphism between 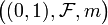 and the perforated interval corresponding to the set
and the perforated interval corresponding to the set
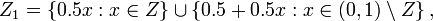
another set of inner Lebesgue measure 0 but outer Lebesgue measure 1.
See also (Rudolph 1990, Exercise 2.11 on page 18).
[edit] A criterion of standardness
Standardness of a given probability space 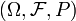 is equivalent to a certain property of a measurable map from to a measurable space
is equivalent to a certain property of a measurable map from to a measurable space 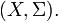 Interestingly, the answer (standard, or not) does not depend on the choice of
Interestingly, the answer (standard, or not) does not depend on the choice of 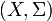 and . This fact is quite useful; one may adapt the choice of and to the given
and . This fact is quite useful; one may adapt the choice of and to the given 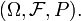 No need to examine all cases. It may be convenient to examine a random variable
No need to examine all cases. It may be convenient to examine a random variable 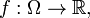 a random vector
a random vector 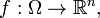 a random sequence
a random sequence 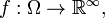 or a sequence of events
or a sequence of events 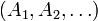 treates as a sequence of two-valued random variables,
treates as a sequence of two-valued random variables, 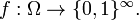
Two conditions will be imposed on (to be injective, and generating). Below it is assumed that such is given. The question of its existence will be addressed afterwards.
The probability space is assumed to be complete (otherwise it cannot be standard).
[edit] A single random variable
A measurable function 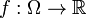 induces a pushforward measure, --- the probability measure
induces a pushforward measure, --- the probability measure 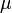 on
on 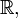 defined by
defined by
-
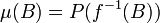 for Borel sets
for Borel sets 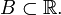
(It is nothing but the distribution of the random variable.) The image 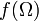 is always a set of full outer measure,
is always a set of full outer measure,
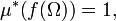
but its inner measure can differ (see a perforated interval). In other words, need not be a set of full measure 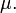
A measurable function is called generating if 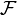 is the completion of the σ-algebra of inverse images
is the completion of the σ-algebra of inverse images 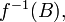 where
where 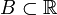 runs over all Borel sets.
runs over all Borel sets.
Caution. The following condition is not sufficient for to be generating: for every 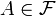 there exists a Borel set such that
there exists a Borel set such that 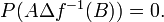 (
(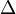 means symmetric difference).
means symmetric difference).
Theorem. Let a measurable function be injective and generating, then the following two conditions are equivalent:
- is of full measure
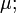
-
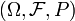 is a standard probability space.
is a standard probability space.
See also (Itô 1984, Sect. 3.1).
[edit] A random vector
The same theorem holds for any 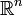 (in place of
(in place of 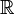 ). A measurable function
). A measurable function 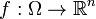 may be thought of as a finite sequence of random variables
may be thought of as a finite sequence of random variables 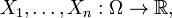 and
and 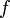 is generating if and only if
is generating if and only if 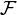 is the completion of the σ-algebra generated by
is the completion of the σ-algebra generated by 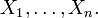
[edit] A random sequence
The theorem still holds for the space 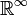 of infinite sequences. A measurable function
of infinite sequences. A measurable function 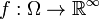 may be thought of as an infinite sequence of random variables
may be thought of as an infinite sequence of random variables 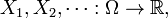 and is generating if and only if is the completion of the σ-algebra generated by
and is generating if and only if is the completion of the σ-algebra generated by 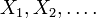
[edit] A sequence of events
In particular, if the random variables 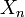 take on only two values 0 and 1, we deal with a measurable function
take on only two values 0 and 1, we deal with a measurable function 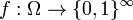 and a sequence of sets
and a sequence of sets 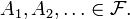 The function is generating if and only if is the completion of the σ-algebra generated by
The function is generating if and only if is the completion of the σ-algebra generated by 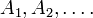
In the pioneering work (Rokhlin 1962) sequences 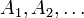 that correspond to injective, generating are called bases of the probability space (see Rokhlin 1962, Sect. 2.1). A basis is called complete mod 0, if
that correspond to injective, generating are called bases of the probability space (see Rokhlin 1962, Sect. 2.1). A basis is called complete mod 0, if 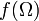 is of full measure
is of full measure 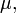 see (Rokhlin 1962, Sect. 2.2). In the same section Rokhlin proved that if a probability space is complete mod 0 with respect to some basis, then it is complete mod 0 with respect to every other basis, and defines Lebesgue spaces by this completeness property. See also (Haezendonck 1973, Prop. 4 and Def. 7) and (Rudolph 1990, Sect. 2.3, especially Theorem 2.2).
see (Rokhlin 1962, Sect. 2.2). In the same section Rokhlin proved that if a probability space is complete mod 0 with respect to some basis, then it is complete mod 0 with respect to every other basis, and defines Lebesgue spaces by this completeness property. See also (Haezendonck 1973, Prop. 4 and Def. 7) and (Rudolph 1990, Sect. 2.3, especially Theorem 2.2).
[edit] Additional remarks
The four cases treated above are mutually equivalent, and can be united, since the measurable spaces 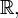
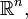 and
and 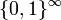 are mutually isomorphic; they all are standard measurable spaces (in other words, standard Borel spaces).
are mutually isomorphic; they all are standard measurable spaces (in other words, standard Borel spaces).
Existence of an injective measurable function from to a standard measurable space does not depend on the choice of Taking 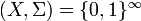 we get the property well-known as being countably separated (but called separable in Itô 1984).
we get the property well-known as being countably separated (but called separable in Itô 1984).
Existence of a generating measurable function from to a standard measurable space also does not depend on the choice of Taking we get the property well-known as being countably generated (mod 0), see (Durrett 1996, Exer. I.5).
| Probability space | Countably separated | Countably generated | Standard |
|---|---|---|---|
| Template:Rh | Interval with Lebesgue measure | |
|
|
| Template:Rh | Naive white noise | |
|
|
| Template:Rh | Perforated interval | |
|
|
Every injective measurable function from a standard probability space to a standard measurable space is generating. See (Rokhlin 1962, Sect. 2.5), (Haezendonck 1973, Corollary 2 on page 253), (de la Rue 1993, Theorems 3-4, 3-5). This property does not hold for the non-standard probability space dealt with in the subsection "A superfluous measurable set" above.
Caution. The property of being countably generated is invariant under mod 0 isomorphisms, but the property of being countably separated is not. In fact, a standard probability space is countably separated if and only if the cardinality of 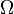 does not exceed continuum (see Itô 1984, Exer. 3.1(v)). A standard probability space may contain a null set of any cardinality, thus, it need not be countably separated. However, it always contains a countably separated subset of full measure.
does not exceed continuum (see Itô 1984, Exer. 3.1(v)). A standard probability space may contain a null set of any cardinality, thus, it need not be countably separated. However, it always contains a countably separated subset of full measure.
[edit] Equivalent definitions
Let be a complete probability space such that the cardinality of does not exceed continuum (the general case is reduced to this special case, see the caution above).
[edit] Via absolute measurability
Definition. is standard if it is countably separated, countably generated, and absolutely measurable.
See (Rokhlin 1962, the end of Sect. 2.3) and (Haezendonck 1973, Remark 2 on page 248). "Absolutely measurable" means: measurable in every countably separated, countably generated probability space containing it.
[edit] Via perfectness
Definition. is standard if it is countably separated and perfect.
See (Itô 1984, Sect. 3.1). "Perfect" means that for every measurable function from to the image measure is regular. (Here the image measure is defined on all sets whose inverse images belong to , irrespective of the Borel structure of ).
[edit] Via topology
Definition. is standard if there exists a topology 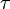 on such that
on such that
- the topological space
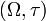 is metrizable;
is metrizable;
- is the completion of the σ-algebra generated by (that is, by all open sets);
- for every
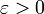 there exists a compact set
there exists a compact set 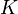 in such that
in such that 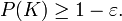
See (de la Rue 1993, Sect. 1).
[edit] Verifying the standardness
Every probability distribution on the space 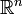 turns it into a standard probability space. (Here, a probability distribution means a probability measure defined initially on the Borel sigma-algebra and completed.)
turns it into a standard probability space. (Here, a probability distribution means a probability measure defined initially on the Borel sigma-algebra and completed.)
The same holds on every Polish space, see (Rokhlin 1962, Sect. 2.7 (p. 24)), (Haezendonck 1973, Example 1 (p. 248)), (de la Rue 1993, Theorem 2-3), and (Itô 1984, Theorem 2.4.1).
For example, the Wiener measure turns the Polish space 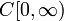 (of all continuous functions
(of all continuous functions 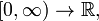 endowed with the topology of local uniform convergence) into a standard probability space.
endowed with the topology of local uniform convergence) into a standard probability space.
Another example: for every sequence of random variables, their joint distribution turns the Polish space 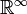 (of sequences; endowed with the product topology) into a standard probability space.
(of sequences; endowed with the product topology) into a standard probability space.
(Thus, the idea of dimension, very natural for topological spaces, is utterly inappropriate for standard probability spaces.)
The product of two standard probability spaces is a standard probability space.
The same holds for the product of countably many spaces, see (Rokhlin 1962, Sect. 3.4), (Haezendonck 1973, Proposition 12), and (Itô 1984, Theorem 2.4.3).
A measurable subset of a standard probability space is a standard probability space. It is assumed that the set is not a null set, and is endowed with the conditional measure. See (Rokhlin 1962, Sect. 2.3 (p. 14)) and (Haezendonck 1973, Proposition 5).
Every probability measure on a standard Borel space turns it into a standard probability space.
[edit] Using the standardness
[edit] Regular conditional probabilities
In the discrete setup, the conditional probability is another probability measure, and the conditional expectation may be treated as the (usual) expectation with respect to the conditional measure, see conditional expectation. In the non-discrete setup, conditioning is often treated indirectly, since the condition may have probability 0, see conditional expectation. As a result, a number of well-known facts have special 'conditional' counterparts. For example: linearity of the expectation; Jensen's inequality (see conditional expectation); Hölder's inequality; the monotone convergence theorem, etc.
Given a random variable 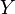 on a probability space , it is natural to try constructing a conditional measure
on a probability space , it is natural to try constructing a conditional measure 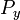 , that is, the conditional distribution of
, that is, the conditional distribution of 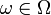 given
given 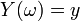 . In general this is impossible (see Durrett 1996, Sect. 4.1(c)). However, for a standard probability space this is possible, and well-known as canonical system of measures (see Rokhlin 1962, Sect. 3.1), which is basically the same as conditional probability measures (see Itô 1984, Sect. 3.5), disintegration of measure (see Kechris 1995, Exercise (17.35)), and regular conditional probabilities (see Durrett 1996, Sect. 4.1(c)).
. In general this is impossible (see Durrett 1996, Sect. 4.1(c)). However, for a standard probability space this is possible, and well-known as canonical system of measures (see Rokhlin 1962, Sect. 3.1), which is basically the same as conditional probability measures (see Itô 1984, Sect. 3.5), disintegration of measure (see Kechris 1995, Exercise (17.35)), and regular conditional probabilities (see Durrett 1996, Sect. 4.1(c)).
The conditional Jensen's inequality is just the (usual) Jensen's inequality applied to the conditional measure. The same holds for many other facts.
[edit] Measure preserving transformations
Given two probability spaces , and a measure preserving map , the image 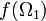 need not cover the whole
need not cover the whole 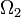 , it may miss a null set. It may seem that
, it may miss a null set. It may seem that 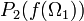 has to be equal to 1, but it is not so. The outer measure of is equal to 1, but the inner measure may differ. However, if the probability spaces , are standard then
has to be equal to 1, but it is not so. The outer measure of is equal to 1, but the inner measure may differ. However, if the probability spaces , are standard then 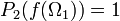 , see (de la Rue 1993, Theorem 3-2). If is also one-to-one then every
, see (de la Rue 1993, Theorem 3-2). If is also one-to-one then every 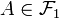 satisfies
satisfies 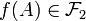 ,
, 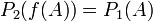 . Therefore is measurable (and measure preserving). See (Rokhlin 1962, Sect. 2.5 (p. 20)) and (de la Rue 1993, Theorem 3-5). See also (Haezendonck 1973, Proposition 9 (and Remark after it)).
. Therefore is measurable (and measure preserving). See (Rokhlin 1962, Sect. 2.5 (p. 20)) and (de la Rue 1993, Theorem 3-5). See also (Haezendonck 1973, Proposition 9 (and Remark after it)).
"There is a coherent way to ignore the sets of measure 0 in a measure space" (Petersen 1983, page 15). Striving to get rid of null sets, mathematicians often use equivalence classes of measurable sets or functions. Equivalence classes of measurable subsets of a probability space form a normed complete Boolean algebra called the measure algebra (or metric structure). Every measure preserving map leads to a homomorphism 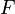 of measure algebras; basically,
of measure algebras; basically, 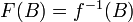 for
for 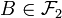 .
.
It may seem that every homomorphism of measure algebras has to correspond to some measure preserving map, but it is not so. However, for standard probability spaces each corresponds to some . See (Rokhlin 1962, Sect. 2.6 (p. 23) and 3.2), (Kechris 1995, Sect. 17.F), (Petersen 1983, Theorem 4.7 on page 17).
[edit] Notes
- ↑ (von Neumann 1932) and (Halmos & von Neumann 1942) are cited in (Rokhlin 1962, page 2) and (Petersen 1983, page 17).
- ↑ Published in short in 1947, in detail in 1949 in Russian and in 1952 in English, reprinted in 1962 (Rokhlin 1962). An unpublished text of 1940 is mentioned in (Rokhlin 1962, page 2). "The theory of Lebesgue spaces in its present form was constructed by V. A. Rokhlin" (Sinai 1994, page 16).
- ↑ "In this book we will deal exclusively with Lebesgue spaces" (Petersen 1983, page 17).
- ↑ "Ergodic theory on Lebesgue spaces" is the subtitle of the book (Rudolph 1990).
[edit] References
- Rokhlin, V. A. (1962), "On the fundamental ideas of measure theory", Translations (American Mathematical Society) Series 1 10: 1–54. Translated from Russian: Рохлин, В. А. (1949), "Об основных понятиях теории меры", Математический Сборник (Новая Серия) 25 (67): 107–150.
- von Neumann, J. (1932), "Einige Sätze über messbare Abbildungen", Annals of Mathematics (3) 33: 574–586.
- Halmos, P. R.; von Neumann, J. (1942), "Operator methods in classical mechanics, II", Annals of Mathematics (2) (Annals of Mathematics) 43 (2): 332–350, doi:10.2307/1968872, JSTOR 1968872.
- Haezendonck, J. (1973), "Abstract Lebesgue–Rohlin spaces", Bulletin de la Societe Mathematique de Belgique 25: 243–258.
- de la Rue, T. (1993), "Espaces de Lebesgue", Séminaire de Probabilités XXVII, Lecture Notes in Mathematics, 1557, Springer, Berlin, pp. 15–21.
- Petersen, K. (1983), Ergodic theory, Cambridge Univ. Press.
- Itô, K. (1984), Introduction to probability theory, Cambridge Univ. Press.
- Rudolph, D. J. (1990), Fundamentals of measurable dynamics: Ergodic theory on Lebesgue spaces, Oxford: Clarendon Press.
- Sinai, Ya. G. (1994), Topics in ergodic theory, Princeton Univ. Press.
- Kechris, A. S. (1995), Classical descriptive set theory, Springer.
- Durrett, R. (1996), Probability: theory and examples (Second ed.).
- Wiener, N. (1958), Nonlinear problems in random theory, M.I.T. Press.
.