Statistics theory

Statistics theory is a mathematical approach to describe something, predict events, or analyze the relationship between things. "Statistics" is a broader concept that also includes the collection, analysis and presentation of numerical data[1]. Statistical analysis can, for example, describe the average income of a population, test whether two groups have the same average income, or analyze factors that might explain the income level for a particular group.
The application of mathematical theory to statistics makes it possible to test relationships between two or more groups or to test how observations compare to a prediction. Some of the statistical concepts include mean (average), standard deviation (how concentrated or spread out things are), and correlation (how related two different variables are). These concepts are further explained in this article.
Statistics theory is used in a very wide variety of fields[2][3] . For example, statistics is used to develop and analyze psychological tests and public opinion surveys, in program evaluation to determine whether a program works or how it can be improved, in medicine with clinical trials to test the safety and effectiveness of new drugs, in engineering to look for outliers and anomalies and to test underlying assumptions[4] and in many other areas.
The usefulness of statistical analysis depends crucially upon the validity of the methods by which data are collected, whether the appropriate statistical techniques are used, whether basic assumptions are met, and how the results are interpreted - matters that are dealt with in more detail in the article on applied statistics. There is also a large variety of free statistical software and most of these packages are pretty useful.
Contents |
[edit] Some basic concepts
Some basic concepts of statistics are easy for anyone to understand. First, statistics is usually divided into descriptive and inferential statistics[5]. Generally, descriptive statistics show what the data look like. Inferential statistics are used to make generalizations or predictions.
One basic idea of descriptive statistics is the measurements of central tendency. Most people know the mean. In general understanding, the mean is the average. Suppose there are five people. The people have, respectively, 1 TV in their house, 4 TVs, 2 TVs, no TVs and 3 TVs. You would say that the 'mean' number of TVs in the house is 2 (1+4+2+0+3)/5=2.
Another measure of central tendency is the median. The median is the point at which half are above and half are below. In the above example, the median is also 2, because in this group of 5 people, 2 people have more than 2 TVs in their house and 2 people have fewer than 2 TVs in their house.
The median is often used in describing incomes of populations because the mean can be misleading. For example, say 9 people have an income of $10,000 a year, and one person has an income of $2,000,000 a year. The average is $2,090,000/10 = $209,000 a year. Really though, only one person really has a very high income and the rest have much lower incomes. In this case, the mean gives a misleading picture of the average income, and the median is usually a better indicator of where the bulk of incomes are.
A slightly more difficult concept in descriptive statistics is the measurements of variation. The standard deviation (SD) is a measure of variation or scatter, or how much things are spread out from the mean. A simple example could again use income. Suppose a community had people with mostly the same incomes, varying from $30,000 to $40,000. Say the average is $35,000. In this case there is little variation or little spread, and so the standard deviation would be pretty small. On the other hand, suppose there is another community where there are a number of wealthy people, some middle income people, and a group of people with low incomes. In this community, the incomes vary from $10,000 a year to $2,000,000 a year. Again, suppose the average is $35,000 a year. However, this second community is clearly different from the first. The two communities have the same average income, but have very different distribution of incomes. In the second community, the standard deviation would be quite large, which is very useful information, describing the large differences between the communities.
One key basic concept of inferential statistics is statistical testing. Suppose a researcher wanted to know whether the two communities described above were the same or were different. The means are the same, but the standard deviations are very different. The question of interest is whether they different enough to say they are significantly different. Statistical testing compares the actual difference to a theoretical difference that might be expected, if, based on theory, the differences were due to chance alone. If the differences are large enough, then the conclusion can be made that there is a real difference, and that the difference is not because of just some chance variation.
[edit] A little more statistical introduction
The theory of statistics refers primarily to a branch of mathematics that specializes in enumeration, or counted, data and their relation to measured data[6][7]. It may also refer to a fact of classification, which is the chief source of all statistics, and has a relationship to psychometric applications in the social sciences. Note that it is debatable whether statistics should be considered a “branch of mathematics” and indeed the consensus among statisticians is that statistics is a scientific discipline that is distinct from mathematics[8][9], just like physics and chemistry. Although mathematics lies at the heart of statistics and is an important tool of statistics, statistics involve several components beyond mathematics [8].
The term statistic refers to a derived numerical value, such as a mean, a coefficient of correlation, or some other single concept of descriptive statistics . It may also refer to an idea associated with an average, such as a median, or standard deviation, or some value computed from a set of data. [10]
More precisely, in mathematical statistics, and in general usage, a statistic is defined as any measurable function of a data sample [11]. A data sample is described by instances of a random variable of interest, such as a height, weight, polling results, test performance, etc., obtained by random sampling of a population.
The usefulness of statistical analysis depends crucially upon the validity of the methods by which statistics are collected, and serious errors have resulted from lack of professional attention to that factor.
[edit] A more statistical illustration
Suppose one wishes to study the height of adult males in some country C. How should one go about doing this and how can the data be summarized? In statistics, the approach taken is to model the quantity of interest, i.e., "height of adult men from the country C" as a random variable X, say, taking on values in [0,5] (measured in metres) and distributed according to some unknown probability distribution[12] F on [0,5] . One important theme studied in statistics is to develop theoretically sound methods (firmly grounded in probability theory) to learn something about the postulated random variable X and also its distribution F by collecting samples, for this particular example, of the height of a number of men randomly drawn from the adult male population of C.
Suppose that N men labeled 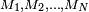 have been randomly drawn by simple random sampling (this means that each man in the population is equally likely to be selected in the sampling process) whose heights are
have been randomly drawn by simple random sampling (this means that each man in the population is equally likely to be selected in the sampling process) whose heights are 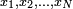 , respectively. An important yet subtle point to note here is that, due to random sampling, the data sample obtained is actually an instance or realization of a sequence of independent random variables
, respectively. An important yet subtle point to note here is that, due to random sampling, the data sample obtained is actually an instance or realization of a sequence of independent random variables 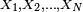 with each random variable Xi being distributed identically according to the distribution of X (that is, each
with each random variable Xi being distributed identically according to the distribution of X (that is, each 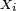 has the distribution F). Such a sequence is referred to in statistics as independent and identically distributed (i.i.d) random variables. To further clarify this point, suppose that there are two other investigators, Tim and Allen, who are also interested in the same quantitative study and they in turn also randomly sample N adult males from the population of C. Let Tim's height data sample be
has the distribution F). Such a sequence is referred to in statistics as independent and identically distributed (i.i.d) random variables. To further clarify this point, suppose that there are two other investigators, Tim and Allen, who are also interested in the same quantitative study and they in turn also randomly sample N adult males from the population of C. Let Tim's height data sample be 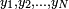 and Allen's be
and Allen's be 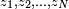 , then both samples are also realizations of the i.i.d sequence , just as the first sample was.
, then both samples are also realizations of the i.i.d sequence , just as the first sample was.
From a data sample one may define a statistic T as 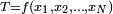 for some real-valued function f which is measurable (here with respect to the Borel sets of
for some real-valued function f which is measurable (here with respect to the Borel sets of 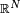 ). Two examples of commonly used statistics are:
). Two examples of commonly used statistics are:
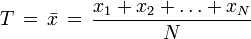 . This statistic is known as the sample mean
. This statistic is known as the sample mean
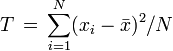 . This statistic is known as the sample variance. Often the alternative definition
. This statistic is known as the sample variance. Often the alternative definition 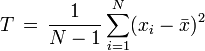 of sample variance is preferred because it is an unbiased estimator of the variance of X, while the former is a biased estimator.
of sample variance is preferred because it is an unbiased estimator of the variance of X, while the former is a biased estimator.
[edit] Transforming data
Statisticians may transform data by taking the logarithm, square root, reciprocal, or other function if the data does not fit a normal distribution.[13][14] Data needs to be transformed back to its original form in order to present confidence intervals.[15]
[edit] Summary statistics
[edit] Measurements of central tendency
- Mean In general understanding, the mean is the average. Suppose there are five people. The people have, respectively, 1 TV in their house, 4 TVs, 2 TVs, no TVs and 3 TVs. You would say that the 'mean' number of TVs in the house is 2 (1+4+2+0+3)/5=2.
- Median The median is the point at which half are above and half are below. In the above example, the median is also 2, because in this group of 5 people, 2 people have more than 2 TVs in their house and 2 people have fewer than 2 TVs in their house.
[edit] Measurements of variation
- Standard deviation (SD) is a measure of variation or scatter. The standard deviation does not change with sample size.
- Variance is the square of the standard deviation:
- s2
- Standard error of the mean (SEM) measures the how accurately you know the mean of a population and is always smaller than the SD.[16] The SEM becomes smaller as the sample size increases. The sample standard devision (S) and SEM are related by:
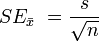
- 95% confidence interval is + 1.96 * standard error.
[edit] Inferential statistics and hypothesis testing
[edit] Problems in reporting of statistics
In medicine, common problems in the reporting and usage of statistics have been inventoried.[17] These problems tend to exaggerated treatment differences.
[edit] References
- ↑ Valparaiso University, Applied Statistics. What is Statistics, http://www.valpo.edu/appstats/index.php, 2009.
- ↑ See the article on applied statistics.
- ↑ University of Nebraska-Lincoln. Department of Statistics. 2006. What is Statistics, http://statistics.unl.edu/whatis.shtml, 2006.
- ↑ NIST/SEMATECH e-Handbook of Statistical Methods, http://www.itl.nist.gov/div898/handbook/, 2006.
- ↑ National Atlas (2008). NationalAtlas.gov http://www.nationalatlas.gov/articles/mapping/a_statistics.html.
- ↑ Trapp, Robert; Beth Dawson (2004). Basic & clinical biostatistics. New York: Lange Medical Books/McGraw-Hill. Template:LCCTemplate:LCCN. ISBN 0-07-141017-1.
- ↑ Mosteller, Frederick; Bailar, John Christian (1992). Medical uses of statistics. Boston, Mass: NEJM Books. ISBN 0-910133-36-0. Google Books
- ↑ 8.0 8.1 D. J. Hand, “Breaking misconceptions-Statistics and its relationship to mathematics”, The Statistician, vol. 47, part 2, pp. 245-250, 1998.
- ↑ D. S. Moore, “Statistics and mathematics: Tension and cooperation”, Online: http://www.stat.purdue.edu/~dsmoore/articles/Statmath.pdf (retrieved on 2009-03-30).
- ↑ Guilford, J.P., Fruchter, B. (1978). Fundamental statistics in psychology and education. New York: McGraw-Hill.
- ↑ Shao, J. (2003). Mathematical Statistics (2 ed.). ser. Springer Texts in Statistics, New York: Springer-Verlag, p. 100.
- ↑ This is the case in non-parametric statistics. On the other hand, in parametric statistics the underlying distribution is assumed to be of some particular type, say a normal or exponential distribution, but with unknown parameters that are to be estimated.
- ↑ Bland JM, Altman DG (March 1996). Transforming data. BMJ 312 (7033): 770. PMID 8605469. PMC 2350481.
- ↑ Bland JM, Altman DG (May 1996). The use of transformation when comparing two means. BMJ 312 (7039): 1153. PMID 8620137. PMC 2350653.
- ↑ Bland JM, Altman DG (April 1996). Transformations, means, and confidence intervals. BMJ 312 (7038): 1079. PMID 8616417. PMC 2350916.
- ↑ What is the difference between "standard deviation" and "standard error of the mean"? Which should I show in tables and graphs?. Retrieved on 2008-09-18.
- ↑ Pocock SJ, Hughes MD, Lee RJ (August 1987). "Statistical problems in the reporting of clinical trials. A survey of three medical journals". N. Engl. J. Med. 317 (7): 426–32. PMID 3614286.
| |
Some content on this page may previously have appeared on Citizendium. |