Statistical significance

Contents |
In statistics, statistical significance is a "term indicating that the results obtained in an analysis of study data are unlikely to have occurred by chance, and the null hypothesis is rejected. When statistically significant, the probability of the observed results, given the null hypothesis, falls below a specified level of probability (most often P < 0.05)."[1] The P-value, which is used to represent the likelihood the observed results are due to chance, is defined at "the probability, under the assumption of no effect or no difference (the null hypothesis), of obtaining a result equal to or more extreme than what was actually observed."[2]
[edit] Hypothesis testing
Usually, the null hypothesis claims that there is no difference between two samples in regard to the factor being studied.[4]
[edit] Choosing a statistical method
The choice of statistical method to use in an analysis is determined by:[5][6][7]
- Type of data, for example: continuous, categorical, dichotomous
- Whether the data is normally distributed. Various normality tests such as the Shapiro-Wilk[8] are available.[9]
- Whether the samples are independent or paired
- Number of samples to compare
[edit] Statistical errors
Two errors can occur in assessing the probability that the null hypothesis is true:
[edit] Type I error (alpha error)
Type I error, also called alpha error, is the rejection of a correct null hypothesis. The probability of this is usually expressed by the p-value. Usually the null hypothesis is rejected if the p-value, or the chance of a type I error, is less than 5%. However, this threshold may be adjusted when multiple hypotheses are tested.[10]
[edit] Type II error (beta error)
Type II error, also called beta error, is the acceptance of an incorrect null hypothesis. This error may occur when the sample size was insufficient to have power to detect a statistically significant difference.[11][12][13]
[edit] Philosophical approaches to error testing
[edit] Frequentist method
This approach uses mathematical formulas to calculate deductive probabilities (p-value) of an experimental result.[2] This approach can generate confidence intervals.
A problem with the frequentist analyses of p-values is that they may overstate "statistical significance".[2][14]
[edit] Likelihood or Bayesian method
Some argue that the P-value should be interpreted in light of how plausible is the hypothesis based on the totality of prior research and physiologic knowledge.[15][2][14][16][17] This approach can generate Bayesian 95% credibility intervals.[18] Details of Bayesian calculations have been reviewed.[19]
The Bayesian method has been proposed for adaptive trial designs for comparative effectiveness research.[20] In the United States, Medicare's Centers for Medicare and Medicaid Services (CMS) is investigating this role.[21]
Bayesian inference:[14]
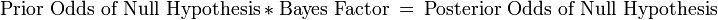
The Bayesian analysis creates a Bayes Factor. Unlike the traditional P-value, the Bayes factor is not a probability of rejecting the null hypothesis, but is a ratio of probabilities. The Bayes Factor is a likelihood ratio. A value greater than 1 supports the null hypotheses, whereas a value less than 1 supports the alternative hypothesis. The equation for the Bayes Factor is:[14]
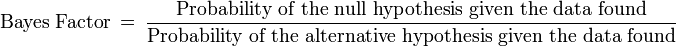
Example of a coin flip that comes up heads in one of four tosses:
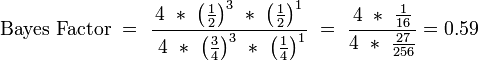
Goodman gives the following three methods of interpreting an example Bayes Factor of 1/2:[14]
- Objective probability: "The observed results are half as probable under the null hypothesis as they are under the alternative."
- Inductive evidence: "The evidence supports the null hypothesis half as strongly as it does the alternative."
- Subjective probability: "The odds of the null hypothesis relative to the alternative hypothesis after the experiment are half what they were before the experiment."
The Minimum Bayes Factor is proposed by Goodman as another way to help readers make Bayesian interpretations if they are accustomed to p-values:[14]
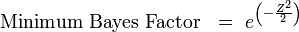
Note that the Minimum Bayes Factor when p = 0.05, or Z= 1.96, is 0.15. This Bayes Factor leads to a posterior probability of 13%, far higher than the 5% probability calculated using frequentist statistics.
| Bayes Factor (B) |
Interpretation of support for the alternative hypothesis |
|---|---|
| > 1.00 | reduces the odds of the null hypothesis |
| 0.32–1.00 | "not worth more than a bare mention" |
| 0.100–0.320 | "substantial support" |
| 0.032–0.100 | "strong support" |
| 0.010–0.032 | "very strong support" |
| < 0.010 | "decisive support" |
A Bayesian approach to interim analysis may help reduce bias and adjust the estimate of effect in randomized controlled trials.[23]
Bayesian analyses provide an alternative to Bonferroni adjustments when testing significance of multiple comparisons.[24]
[edit] References
- ↑ Anonymous. JAMAevidence Glossary. American Medical Association. Retrieved on 2009-02-10.
- ↑ 2.0 2.1 2.2 2.3 Goodman SN (1999). Toward evidence-based medical statistics. 1: The P value fallacy. Ann Intern Med 130: 995–1004. PMID 10383371.
- ↑ Anonymous (2006). “Normal Distribution”, NIST/SEMATECH e-Handbook of Statistical Methods. Gaithersburg, MD: National Institute of Standards and Technology. Retrieved on 2009-02-10.
- ↑ Mosteller, Frederick; Bailar, John Christian (1992). Medical uses of statistics. Boston, Mass: NEJM Books. ISBN 0-910133-36-0. Google Books
- ↑ Ludford PJ. An Overview: Choosing the Correct Statistical Test. University of Minnesota.
- ↑ How to choose a statistical test. GraphPad.
- ↑ Dinov I. Choosing the Right Statistical Test. University of California at Los Angeles.
- ↑ Shapiro, S. S. and Wilk, M. B. (1965). "An analysis of variance test for normality (complete samples)", Biometrika, Vol. 52, No. 3/4, pages 591–611. Template:Doi
- ↑ Stephens, M. A. (1974). "EDF Statistics for Goodness of Fit and Some Comparisons". Journal of the American Statistical Association 69: 730–737. DOI:10.2307/2286009. Research Blogging.
- ↑ Hochberg, Yosef (1988-12-01). A sharper Bonferroni procedure for multiple tests of significance. Biometrika 75 (4): 800-802. DOI:10.1093/biomet/75.4.800. Retrieved on 2008-10-15. Research Blogging.
- ↑ Altman DG, Bland JM (August 1995). Absence of evidence is not evidence of absence. BMJ (Clinical research ed.) 311 (7003): 485. PMID 7647644. PMC 2550545.
- ↑ Detsky AS, Sackett DL (April 1985). "When was a "negative" clinical trial big enough? How many patients you needed depends on what you found". Archives of internal medicine 145 (4): 709–12. PMID 3985731.
- ↑ Young MJ, Bresnitz EA, Strom BL (August 1983). "Sample size nomograms for interpreting negative clinical studies". Annals of internal medicine 99 (2): 248–51. PMID 6881780.
- ↑ 14.0 14.1 14.2 14.3 14.4 14.5 Goodman SN (1999). Toward evidence-based medical statistics. 2: The Bayes factor.. Ann Intern Med 130 (12): 1005–13. PMID 10383350.
- ↑ Browner WS, Newman TB (1987). "Are all significant P values created equal? The analogy between diagnostic tests and clinical research". JAMA 257: 2459–63. PMID 3573245.
- ↑ Diamond GA, Kaul S (June 2004). Prior convictions: Bayesian approaches to the analysis and interpretation of clinical megatrials. J. Am. Coll. Cardiol. 43 (11): 1929–39. DOI:10.1016/j.jacc.2004.01.035. PMID 15172393. Research Blogging.
- ↑ Ioannidis JP (August 2008). Effect of formal statistical significance on the credibility of observational associations. Am. J. Epidemiol. 168 (4): 374–83; discussion 384–90. DOI:10.1093/aje/kwn156. PMID 18611956. Research Blogging.
- ↑ Gelfand, Alan E.; Sudipto Banerjee; Carlin, Bradley P. (2003). Hierarchical Modeling and Analysis for Spatial Data (Monographs on Statistics and Applied Probability). Boca Raton: Chapman & Hall/CRC. Template:LCC. ISBN 1-58488-410-X.
- ↑ Greenland S (June 2006). Bayesian perspectives for epidemiological research: I. Foundations and basic methods. Int J Epidemiol 35 (3): 765–75. DOI:10.1093/ije/dyi312. PMID 16446352. Research Blogging.
- ↑ Luce BR, Kramer JM, Goodman SN, et al. (June 2009). Rethinking Randomized Clinical Trials for Comparative Effectiveness Research: The Need for Transformational Change. Ann. Intern. Med. 151 (3). PMID 19567619.
- ↑ Anonymous. Health Care: Technology Assessment Subdirectory Page (English). Agency for Healthcare Research and Quality. Retrieved on 2009-08-03.
- ↑ Jeffreys, Harold [1961] (1998). Theory of probability. Oxford: Clarendon Press. ISBN 0-19-850368-7.
- ↑ Goodman SN (June 2007). Stopping at nothing? Some dilemmas of data monitoring in clinical trials. Ann. Intern. Med. 146 (12): 882–7. PMID 17577008.
- ↑ Greenland S (June 2008). Multiple comparisons and association selection in general epidemiology. Int J Epidemiol 37 (3): 430–4. DOI:10.1093/ije/dyn064. PMID 18453632. Research Blogging.
[edit] External links
| |
Some content on this page may previously have appeared on Citizendium. |