Unicode

Contents |
Unicode is a universal character encoding standard maintained by an international non-profit organization, the Unicode Consortium. "Encoding a character" simply means assigning a unique whole number to a character. The aim of Unicode is to number all the individual characters of all scripts in the world. At present (2014) Unicode supports 119 scripts, among them Arabic, Cyrillic, Egyptian Hieroglyphs, Han (Chinese characters), Hebrew, Linear B (an early Greek script), and of course Latin (Western script), with a total of about 112 000 numbered and named characters. The numbers encoding characters are called code points; usually they are given in the hexadecimal (hex) number system,[1] because that gives a more compact representation of a number than the daily-life decimal (dec) system.

Unicode does not define the actual rendering of letters (the "glyphs") associated with code points, this is left to users of Unicode, such as World-Wide-Web (WWW) browsers and word processors. See Fig. 1 where different possible renderings are illustrated for one and the same code point (number 65 corresponding to the capital letter A). It is up to the text processor to render the code point as glyph. Most text processors have more than one font at their disposal, so information (which can be set by default) in addition to the Unicode code point is necessary to select the font and therewith the actual glyph that is printed or shown on the screen.
[edit] Overview of Unicode
Unicode, Inc. was incorporated on January 3, 1991 with the purpose to "standardize, extend and promote the Unicode character encoding, a fixed-width, 16-bit character encoding for over 60 000 graphic characters." In principle a 16-bit storage unit can hold 65 536 characters, but it soon appeared to the consortium that more than 16 bits are needed to hold the characters of all existing scripts.
Because the collection of Latin (Western) upper- and lowercase letters (without accents or other diacritics) plus punctuation marks contains less than 128 characters, the first encoding of the Latin script was a 7-bits code called ASCII (American Standard Code for Information Interchange). ASCII was established in 1963. An 8-bit extension (room for 256 characters) to ASCII, including letters with accents like é and ü, appeared on the IBM-PC in 1981 under the name "extended ASCII"; sometimes extended ASCII is referred to as the OEM (Other Equipment Manufacturer) character set. In 1987, the encoding of the 256 most common characters in Western scripts (including letters with diacritics) was standardized by the International Organization for Standardization (ISO) under the name ISO 8859-1 (Latin-1, also referred to as ISO/IEC 8859-1, because the International Electrotechnical Commission also endorses the standard). It must be noted that the ISO 8859-1 characters above 0x007F = 127 do not coincide with those of the extended ASCII standard used under DOS (operating system on early IBM-PC's). The first 128 Unicode characters (0x0000 to 0x007F) and their encoding are identical to those in ASCII and the range 0x0080 to 0x00FF (128 to 255) of Unicode code points is identical to ISO/IEC 8859-1.
As the solution to the problem that more than 65 536 characters must be handled, Unicode defines 17 groups (called planes) of 16-bit numbers (represented by four hexadecimal digits) in the range 0x00 0000 to 0x10 FFFF. The planes are consecutively numbered by 17 numbers, in hexadecimal form they are: 0x00, 0x01, ..., 0x10. The planes allow handling of over one million unique characters (to be precise: 17×65 536 = 1 114 112). Only planes 0 and 1 are fully defined at the moment, plane 3 is partially defined, and the other 14 planes are for future use. Plane 0 (also known as the Basic Multilingual Plane, BMP) contains the most frequently used characters. The code points in the BMP take 16 bits of storage, because leading zeros (i.e., to the left of bit 16) are implied; for code points in the higher planes one needs to store the plane number as well, which requires at least 5 extra bits.
The definition of code points does not necessarily mean that Unicode characters are stored as the bits strings that represent the code points. One could imagine, for instance, that 24 bits (3 bytes) are used to store all Unicode characters, because three bytes are enough to store all code points up to and including 0x10 FFFF, the highest value in plane (10)hex. However, this would not be a good idea, because it would need converting all computer documents (programs and other texts) that were created before Unicode came into existence (or accept them as unreadable under the Unicode standard). Further all legacy programs that read and write ASCII files would have to be modified, which is completely out of the question because of the manpower required for this conversion.
Unicode defines three different ways in which code points may be stored. One of the storage schemes (UTF-16) stores the code points of the BMP (plane 0) unchanged in 16-bit form, but for the higher planes UTF-16 needs more than 16 bits. The three Unicode storage schemes (UTF-8, UTF-16, and UTF-32) will be discussed below, in section UTF. Legacy texts in ASCII (characters below 128) are readable and modifiable under the Unicode UTF-8 standard, which stores characters above 127 in variable length bit strings. The code points between 128 and 255 are stored as 16 bits in UTF-8, whereas ISO 8859-1 stores the very same code points in 8 bits.
Characters from Latin-based scripts (including accented letters) require 1.1 byte (9 bits) on average in UTF-8. Greek, Arabic, Hebrew, and Russian require an average of 1.7 byte (14 bits). Finally, Japanese, Korean, and Chinese typically require 3 bytes (24 bits) per character.[2]
[edit] Entering Unicode in text
The first 128 characters (code points between U+0000 and U+007F, i.e., from 0 to 127) are defined here. To use them in HTML (hypertext markup language) used on the Web, one precedes them with &#x and ends them with a semicolon. For instance, three HTML renderings of ordinary Latin-1 characters are:
- 1 → 1
- A → A
- ~ → ~
(Of course, entering these characters by hitting the appropriate key on the keyboard is easier than using these codes.) The Unicode consortium indicates these characters by U+0031, U+0041, and U+007E, respectively, that is by U+ followed by the code point in hex.
In computer languages like Java and JavaScript one includes Unicode in a string preceded by \u. For instance:
- var s = "Bob's caf\u00E9 charges \u20AC 2.25 for a beer"; .
The content of the string s is: Bob's café charges € 2.25 for a beer.
The code points between 0x0080 and 0x00FF are defined here. Characters in this range are Latin letters with diacritics such as, for example,
- À → À
- Ø → Ø
It must be pointed out that decimal representations are also applicable in HTML, in that case x (indicating hex) is omitted. Thus, for example, the following are valid HTML,
- À → À
- Ø → Ø
Note that (192)dec = (00C0)hex, and (216)dec = (00D8)hex.
The first 256 (Western) characters (Latin-1) are standard and rendered by very similar glyphs in all Web browsers and other text processors. However, because the rendering is left to the browsers, the glyphs of code points above 255 may appear differently (or not at all) in different web browsers. Following are two examples of non Latin-1 characters that may, or may not, be rendered correctly:
| € | → € | € | → € |
| ⊕ | → ⊕ | ⊕ | → ⊕ |
where (8364)dec = (20AC)hex and (8853)dec = (2295)hex. See for an overview of all Unicode charts this site.
The World Wide Web Consortium (W3C) took a number of frequently used Unicode characters and defined mnemonics for them, see Character entity reference. For instance, the following four designations are for the same character (c-cedilla, used in the French language):
- U+00E7, ç, ç, ç → ç
where ç is the W3C mmemonic for the character. A fifth way to represent the letter ç is as composed character, see below. The W3C mnemonics can be used freely in HTML documents.
[edit] Composed characters
Some code points have been assigned to combining characters. These are similar to the non-spacing accent keys on a typewriter. A combining character is not a full character by itself: it is an accent or other diacritical mark that is added to the previous character. In this way it is possible to place any accent on any character. The most important accented characters have codes of their own. They are known as precomposed characters. Precomposed characters are available for backward compatibility with older encodings that have no combining characters, such as ISO 8859.
Combining characters follow the character which they modify. For example, the German umlaut character ü can either be represented by the precomposed code U+00FC, or alternatively by the combination of a normal letter u (U+0075) followed by a combining diaeresis: U+0075 U+0308, that is, ü → ü. Several combining characters can be applied when it is necessary to stack multiple accents or add combining marks both above and below the base character.
Some more examples, (see the U0300-chart for codes of diacritical marks)
- ö → ö
- r̅ → r̅
- x̅ → x̅
- ç → ç
[edit] Unicode and ISO 10646
In the late 1980s the International Organization for Standardization (ISO) started a project to create a single Universal coded Character Set (UCS). This initiative occurred almost simultaneous with the first steps with the same goals taken by the Unicode Consortium. In 1991 the two projects joined their efforts and worked together on creating a single code table containing all characters of all scripts. Both projects still exist and publish their respective standards independently, but they have agreed to keep the code tables of the Unicode and ISO 10646 standards compatible. The latest (2012) ISO standard of the UCS is ISO/IEC 10646:2012 (IEC also participates), see this site.
[edit] UTF
As discussed above, UCS and Unicode are in fact code tables in which integer numbers (code points) are assigned to characters. A text consists of a sequence of characters—in one-to-one correspondence with code points—that on a computer is represented by a sequence of bytes (a byte is a contiguous sequence of eight bits). There exist several alternatives of representing a sequence of code points by a sequence of bytes. These possibilities are indicated by the letters UTF, standing for UCS Transformation Format or Unicode Transformation Format.
The two most obvious encodings store a code point directly either as two or four bytes (16 or 32 bits). These encodings are known as UTF-16 and UTF-32, respectively. An ASCII file can be transformed into a UTF-16 file by simply inserting a byte containing 00 in front of every ASCII byte. The 2-byte code points in the BMP are stored directly. For the higher planes the UTF-16 procedure for storing is somewhat more cumbersome requiring a pair of 16-bit ("surrogate") units, see Unicode FAQ. For a UTF-32 file, one must insert three 00 bytes before every ASCII byte. As already discussed, this simplistic solution leads to problems. Almost all of the existing Unix, Windows, and Mac software expects ISO 8859-1 (Latin-1, one byte per character) files and would need major recoding to read 16- or 32-bit words as characters. Therefore, UTF-16 and UTF-32 are not suitable external encodings for filenames, text files (including program text), environment variables, etc. Internally the UTF-16 and UTF-32 codes can be useful, provided a translation is made after reading from an external device and before writing to it. JavaScript stores strings internally as UTF-16 code.
[edit] UTF-8
The Unicode UTF-8 storage scheme is used frequently, a main reason being that it is completely backward compatible with 7-bit ASCII and to some extent with 8-bit ISO 8859-1 and Windows code page 1252 (the latter two codes coincide largely). In 2014 more than 75% of the websites used UTF-8, and a very large fraction of the remaining sites still used ASCII, ISO/IEC 8859-1, or Windows-1252; sites using other character sets are a minute minority.[3][4] Much of e-mail is also encoded in UTF-8, as are the latest versions of Linux; the present article is stored in Unicode UTF-8.
UTF-8 is in fact an algorithm for the transformation of an arbitrary string of 32 bits into another string of length varying from 8 to 48 bits (1 to 6 bytes). Because UTF-8 describes the transformation of an arbitrary bit string, its application is not restricted to Unicode code points.
The transformation of a bit string S1 to its UTF-8 representation S2 is by means of Table 1. This table is organized such that the first three rows give the transformation of the entries in the BMP (16 bit code points). The next row is for the transformation of code points in the higher planes; row 5 and 6 are not used in Unicode. First the numerical value V of S1 is determined and it is decided in which of the six following intervals (given in hex) it belongs:
- 0 ≤ V ≤ 7F; 80 ≤ V ≤ 7FF; 800 ≤ V ≤ FFFF (BMP).
- 1 0000 ≤ V ≤ 1F FFFF; 20 0000 ≤ V ≤ 3FF FFFF; 400 0000 ≤ V ≤ 7FFF FFFF.
Depending on the interval, S1 is transformed to a bit string S2 of length varying from one (first interval) to six (sixth interval) bytes. In this transformation the least significant (rightmost) 7, 11, 16, 21, 26, or 31 bits of S1 are transferred to S2, again depending on the interval. The six rows of Table 1 correspond to the intervals. In this table, the bits of S2 originating from S1 are indicated by x′s. The most significant (leftmost) bits of the one to six bytes constituting S2 are set as shown in the table.
| Boundaries of V (hex) | Bit string S2 |
| 00 – 7F | 0xxxxxxx |
| 080 – 7FF | 110xxxxx 10xxxxxx |
| 0800 – FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 01 0000 – 1F FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
| 0020 0000 – 03FF FFFF | 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx |
| 0400 0000 – 7FFF FFFF | 1111110x 10xxxxxx 10xxxxxx 10xxxxxx10xxxxxx 10xxxxxx |
Example of a transformation:
Consider S1 = U+0180 → ƀ and transform to a bit string:
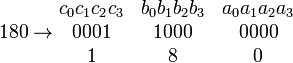
From inspection of the x′s in the second row of Table 1, it follows that eleven bits c1 through a3 must be transferred as follows:
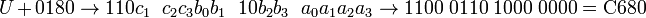
Windows-7 or Vista users can verify this UTF-8 transformation as follows. Execute special characters (c:\windows\system32\charmap.exe) and a window with many of the U+xxxx (BMP, plane 0) codes will open up. Paste U+0180 (ƀ) into Notepad and save from Notepad as UTF-8. Open the saved file with a hex-editor and the UTF-8 BOM (byte order mark) EFBBBF followed by the UTF-8 code C680 is shown. Other example: xU+034C renders as x͌ and has UTF-8 code 78CD8C, with (78)hex the ASCII / UTF-8 code for x and CD8C the UTF-8 code for the diacritical mark U+034C (double tilde). JavaScript programmers may use encodeURI() for BMP characters. This function returns the UTF-8 code separated by % signs. For instance ᴌ (ᴌ): encodeURI("\u1d0c") returns %E1%B4%8C.
One of the advantages of UTF-8 is the relatively easy determination of the string S2 to which an arbitrary byte in a UTF-8 file belongs: Read a byte and inspect its most significant (leftmost) bit 8. If bit 8 is not set (equals zero) the byte represents a 7-bit ASCII character (row 1 in Table 1). If bit 8 is set, inspect the bit to the immediate right of it, bit 7. If bit 7 is not set, the byte is in the middle of an UTF-8 string; backup one byte and inspect it. If this byte again starts with bits 10, back up again, until a byte is found of which bits 7 and 8 are set (two most significant bits contain 11). Then inspect bit 6, if this is not set (zero) we know that we have found the first byte of a string of two bytes. If bit 6 is set, inspect bit 5, if this is not set the string consists of three bytes, and so on. Once the appropriate number of one to six bytes is found giving S2, it is an easy matter to extract the bits from it (the x′s in Table 1) and to reconstitute the Unicode code point S1 numbering the character. It is then up to the text processor to render S1 on paper or screen.
False matches (a bit string in a file that looks like a valid character) never occur in UTF-8 because the end of one sequence can never be the same as the start of another sequence. The algorithm is such that if one randomly accesses into text, the nearest code-point boundaries can always be found with a small number of machine instructions.
[edit] UTF-8 versus ISO 8859-1
At present the two encodings most frequently used (at least by authors writing in Western scripts) are Unicode UTF-8 and ISO/IEC 8859-1 (Latin-1). It is useful, therefore, to summarize their differences. Both encodings are identical (have same code points) below 256. Below 128 both sets of characters are stored as 8-bit strings that are identical to 7-bit ASCII codes augmented with an eighth (most significant) bit that is set to zero. Between 128 and 255 UTF-8 and Latin-1 store their code points differently. Whereas Latin-1 stores the code point unchanged as an 8-bit binary number, UTF-8 transforms it to a 16-bit (two byte) string before storing. Above code point 255 Latin-1 is not defined, while Unicode has a maximum code point with a value of over a million (1 114 111).
As an example, consider the letter e with sharp accent: é. In both encodings it has code point E9 (233). In Latin-1 it is stored directly as the bit string E9 = 1110 1001 (one byte). In UTF-8 it is stored by application of the algorithm discussed above as the 16 bit string C3 A9 = 1100 0011 1010 1001. Now, the leftmost byte 1100 0011 (= C3) is the Latin-1 representation for à and 1010 1001 (= A9) is the Latin-1 representation for ©. Hence, if you, by accident, look at an UTF-8 file containing the letter é with a browser that is set for ISO-8859-1 you will see é instead of é. Conversely, if a Latin-1 character (above 127) is not recognizable as an UTF-8 string, a browser set for UTF-8 will give a warning character, for instance �.
[edit] Supported scripts
The 119 scripts currently (June 2014) supported by Unicode 7.0 are: [5]
|
|
|
- ↑ Following usage in the C programming language hexadecimal numbers are often prefixed by 0x, for instance 0xFE1 = (4065)dec, but also by subscript hex, e.g. (FE1)hex, or subscript 16 as (FE1)16.
- ↑ Mark Davis 1999
- ↑ In 2010 nearing 50%
- ↑ In 2011 passing 50%
- ↑ Unicode supported scripts, see Unicode site
[edit] Links to code charts
Links to some selected code charts made available by the Unicode Consortium are given together with the lowest code point of the chart. Some of the files contain more than one chart, in that case more than one code point is given.
- Latin-1 (ASCII) U+0000
- Latin-1 Supplement U+0080
- Latin Extended-A U+0100
- Latin Extended-B U+0180
- IPA Extensions U+0250
- Spacing Modifier Letters U+02B0
- Combining Diacritical Marks U+0300
- Greek U+0370
- Cyrillic U+0400
- Cyrillic Supplement U+0500
- Roman Symbols U+10190
- Rumi Numeral Symbols U+10E60
- Phonetic Extensions U+1D00
- Musical Symbols U+1D100
- Mathematical Alphanumeric Symbols U+1D400, 1D500, 1D600, 1D700
- Phonetic Extensions Supplement U+1D80
- Combining Diacritical Marks Supplement U+1DC0
- Latin Extended Additional U+1E00
- Greek Extended U+1F00
- Mahjong Tiles U+1F000
- Domino Tiles U+1F030
- Playing Cards U+1F0A0
- Enclosed Alphanumeric Supplement U+1F100
- Miscellaneous Symbols And Pictographs U+1F300, 1F400, 1F500
- Emoticons U+1F600
- Alchemical Symbols U+1F700
- General Punctuation U+2000
- Superscripts and Subscripts U+2070
- Currency Symbols U+20A0
- Combining Diacritical Marks for Symbols U+20D0
- Letterlike Symbols U+2100
- Number Forms U+2150
- Arrows U+2190
- Mathematical U+2200
- Miscellaneous Technical U+2300
- Control Pictures U+2400
- Optical Character Recognition (OCR) U+2440
- Enclosed Alphanumerics U+2460
- Box Drawing U+2500
- Block Elements U+2580
- Geometric Shapes U+25A0
- Chess/Checkers U+2600
- Dingbats U+2700
- Miscellaneous Mathematical Symbols-A U+27C0
- Supplemental Arrows-A U+27F0
- Supplemental Arrows-B U+2900
- Miscellaneous Mathematical Symbols-B U+2980
- Supplemental Mathematical Operators U+2A00
- Additional Arrows U+2B00
- Miscellaneous Symbols and Arrows U+2B00
- Latin Extended-C U+2C60
- Cyrillic Extended-A U+2DE0
- Supplemental Punctuation U+2E00
- Cyrillic Extended-B U+A640
- Modifier Tone Letters U+A700
- Latin Extended-D U+A720
- Latin Ligatures U+FB00
- Vertical Forms U+FE10
- Combining Half Marks U+FE20
- Small Form Variants U+FE50
- Fullwidth ASCII Punctuation U+FF00