NP complexity class

Contents |
The NP complexity class (Non-deterministic Polynomial time) consists of all types of yes/no questions where whenever the answer is yes, there is an easily verifiable proof of this fact. For example, the traveling salesman problem has as input a set of cities, the cost of available transit links between them, and a budget. The question is whether or not there exists an order in which a salesperson can visit all of the cities without exceeding the budget. The easily verified proof in this case is simply the order to visit the cities. The definition of "easily verifiable" is that the verification can be done in time polynomial in the length of the input. See technicalities section for formal definitions of these terms.
A type of yes/no question is called a decision problem. Any decision problem that can be solved in polynomial time, such as "does 24554+254=5987987", is in NP - just use "trivial" as the proof. A natural question arises - what is the hardest problem in NP? The way to compare the hardness of problems is polynomial-time reductions. Problem B reduces to problem C if one could use a polynomial-time solution to problem C to solve problem B in polynomial time. Theoretically, problem B is no harder than problem C.
It turns out that every problem in NP reduces to the traveling salesman problem. The traveling salesman problem is not special in this regard; there are hundreds of so-called NP-hard problems which any problem in NP can be reduced to. If a problem is both NP-hard and in NP, it is NP-complete. NP-complete problems capture the essence of NP, so informal references to NP are usually references to NP-completeness.
Put another way, the NP-complete problems all have a certain hardness. Problems in NP are the ones that are no harder than the NP-complete ones, and problems that are NP-hard are at least as hard.
It is widely suspected that no NP-complete problem can be solved in polynomial time, but this has not been proven. The 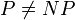 question is one of the greatest open problems in computer science and mathematics; the Clay math institute has offered a $1 million US dollar prize for a solution.
question is one of the greatest open problems in computer science and mathematics; the Clay math institute has offered a $1 million US dollar prize for a solution.
[edit] Definitions
For any problem of interest here, there is some parameter which acts as an indicator of problem size — the number of equations or variables in a system to be solved, bits in a number to be factored, bodies in a gravity problem, nodes in a network, whatever is appropriate to the problem. Call it s for size. The amount of computation (call it C) required to solve the problem will vary with s, say C = f(s). The question is, how does it vary?
For many problems, f(s) is some polynomial in s for some algorithm that runs on a deterministic machine — a Turing machine, or any Turing-equivalent computer, more-or-less any conventional single-processor machine. We call the class of all such problems P for polynomial time.
NP, for non-deterministic polynomial, is the class of problems that can be solved in polynomial time on a non-deterministic machine. There are several equivalent ways to define such a machine:
- given an answer, it can be checked for correctness in polynomial time on a deterministic machine
- given an oracle that tells you which branch to try first, the problem can be solved in polynomial time — just check the correct answer
- given enough parallelism, the problem can be solved in polynomial time — just check all possible answers in parallel
The difficulty is that when a real problem is to be solved, you have neither an answer that only needs checking nor an oracle to give you one. The only feasible methods are to use a parallel machine or to emulate one with a series of calculations on a single deterministic machine. Those techniques may work well for some problems. In particular, if the number of alternatives to be considered is a polynomial in s and the time to check one is another polynomial in s, then the time to check them all on a single deterministic machine is just the product of those two polynomials. That is another polynomial in s, so the problem is in P.
However, for many problems in NP the number of alternatives to be considered grows too quickly for that to work. In particular, if the number of possible answers grows exponentially with problem size, then an algorithm for a deterministic machine that just checks all possible answers sequentially must take exponential time even though any one answer can be checked in polynomial time.
What is not known for the difficult cases is whether some other algorithm might solve such problems in polynomial time on a deterministic machine. Whether, given that a problem is in NP (any answer can be checked in polynomial time on a deterministic machine), an algorithm (for a deterministic machine) must exist to find an answer in polynomial time. If such algorithms exist for all problems in NP, then all those problems are also in P, and we can summarise this as P=NP. If for some problems no such algorithm is possible, then those problems are in NP but not in P so P≠NP.
Obviously any problem in P is also in NP. If the problem can be solved in polynomial time on a deterministic machine, then it can be solved at least as fast on the more powerful non-deterministic machine.
However, it is an open problem whether all problems in NP are in P. No counter-example is known, no problem that is provably in NP and provably not in P. Nor is there, as of mid-2010, any accepted proof either that P=NP or P≠NP. There have, however, been many attempts at such proofs.
[edit] P, NP and reductions
[edit] Optimization problems
The definition of NP given above is for yes/no (decision) problems only. However, many natural problems are optimization problems. For example, a real-world traveling salesman does not have a fixed budget, but rather wants to make the trip at the lowest possible cost. Optimization problems are considered in this framework by considering a decision variant. For example, the decision variant of the traveling salesman problem is the question of whether or not there exists a tour with cost less than a given value. An optimization problem is classified as being NP-hard, in NP or NP-complete based on the classification of its decision variant.
[edit] Variants
- Strongly NP hard
- the problem is still NP-hard if all numbers in the problem are expressed in unary.
- Weakly NP hard
- the problem is polynomial-time solvable if all numbers in the problem (rather than their logarithms) are bounded by the problem size.
[edit] Example problems whose hardness is unknown
There are many problems in computer science with no known polynomial time algorithms. Many of these problems are NP-complete, but some are not. Some problems, such as propositional logic with quantifiers, are not known to be in NP because there are no short proofs for the yes instances. Many other problems are known to be in NP, but are not known to be NP-hard; three examples follow.
The general problem of integer factorisation, determining the factors of a composite integer, is famously difficult. Some factors may be easy — for example, 2 is a factor of any even number — but finding all the factors is hard in the worst case. A well-known example is the moduli used in the RSA algorithm for public key cryptography; an RSA modulus is a product of two primes, each of a few hundred bits.
Factoring is clearly in NP; checking a purported factorisation is straightforward, just multiply the factors together. However it is not known whether or not it is NP hard. Factoring n as such is not a decision problem, but one can ask the question of whether n has a factor less than m. The related decision problem of determining whether an integer is prime or composite was recently shown to be in P. [1][2]. Remarkably, one can show that a number is composite without discovering a factor!
Determining whether or not two given graphs are isomorphic is another important problem which is not known to either be polynomial-time solvable or NP-complete.
Nash equilibria always exist, but no polynomially-time procedure to find one is known. Finding a Nash equilibrium is not a decision problem, so a different complexity class, PPAD, is used.
[edit] Solving NP-complete problems
NP-complete problems are extremely important in applications, so one cannot simply give up when a problem is shown to be NP-hard. Fortunately, there are many ways to get around NP-hardness. The easiest solution is to reduce the problem one is trying to solve to a classic problem, and use someone else's solver that problem. NP hardness is an asymptotic result of worst-case instances, so it is often possible to use branch and bound to solve the instances one cares about in a reasonable amount of time. Local search techniques cannot generally be proven to work well, but they often work excellently in practice. For optimization problems, one can find a solution that is suboptimal in one sense or another (rather than optimal).
[edit] Reducing to a well-known problem
Two NP-complete problems are particularly important because many other problems can be easily reduced to them: 3-SAT and Integer Programming.
Satisfiability is determining whether or not a given Boolean formula in conjunctive normal form admits an assignment of values to the variables which satisfies all the clauses. The special-case of 3-SAT is the restriction of satisfiability to 3 variables per clause; one can easily convert a general satisfiability problem into a 3-SAT problem by adding extra variables and splitting clauses.
Integer programming is a special case of mathematical programming. An integer program is an optimization problem with a linear objective function, linear constraints, and constraints that some or all of the variables must be integers.
If one removes the constraint that the variables be integer-valued and allows them to be real-valued, the result is the linear relaxation of the problem, a linear program. Linear relaxations are crucial both for branch and bound and approximation algorithms.
[edit] Branch and Bound
What might a human do when attempting to choose the absolute best route for a salesman to visit 12 cities? One possibility is to systematically enumerate every possible tour. Now suppose that one is considering a tour that starts by visiting San Francisco, then Cambridge (England), then New York, then London, then Boston. This is clearly a ridiculous way to start the tour. It would be really boring to consider all possible ways to visit the remaining cities, so one may wonder if there's a way to show that the optimal tour does not start this way. There are at least two general ways to do this.
One can start the tour with the same 5 cities, but visit them in the more natural order SF, NY, Cambridge, London, Boston instead, saving a round-trip trans-Atlantic flight. Now, if you take any tour that starts with SF, C, NY, L, B, you can make it better by starting with SF, NY, C, L, B instead and then visiting the remaining cities in the same order as before. Therefore, we can stop considering this bad order. This is called dominance detection.
The above technique allows one to stop considering some orders that are clearly non-optimal, but has serious drawbacks. For example, how do you know if there's a better way to visit the cities you have considered so far? That's almost begging the question.
Another technique, called relaxations, is more popular. (In artificial intelligence circles, the same concept is called an admissible heuristic.) Suppose, optimistically, that our traveling salesman could teleport for free to any place he has already visited. This obviously makes life easier; for example, the salesman only has to buy one trans-Atlantic ticket as he can teleport home. Therefore, if one could show that even if the salesman gained this ability the partial tour being considered would be too expensive, then in the real world, the partial tour can be discarded. It turns out that the teleporting salesman is precisely the minimum spanning tree problem, which can be solved pretty easily in polynomial time. The general principle is that if you can show that a partial solution would be more expensive than the best complete solution you've found, even if the partial solution gets extra powers, then the partial solution can be discarded.
Branch and bound is an algorithmic technique with two intermixed steps. In the "branch" step, one divides the solution space into two or more pieces, for example consider separately tours that visit Boston after New York and those that do not. This is like a mathematician's proof by cases. In the "bound" step, one tries to prove that the newly created partial tours are not optimal and can therefore be discarded.
Branch and bound is a framework for algorithms, not a specific algorithm, so there are many branch and bound-based algorithms for a single problem such as TSP. For example, the branch and bound framework does not specify in what order the partial tours are considered. A technique called best-first-search (in artificial intelligence terminology, A*/Z*) can be proven to consider the fewest possible number of partial tours, but it is memory intensive so variants of depth-first-search are more commonly used in practice.
[edit] Local Search and other heuristic approaches
In computer science, a heuristic is a technique which works in practice but comes with no theoretical guarantees of performance.
Local search techniques start with a solution and try to improve it. Local search techniques include:
- Simulated annealing
- inspired by nature's ability to find low-energy configurations in statistical physics, accept moves that reduce the quality of the solution with probability
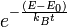 . Some simulated annealing algorithms can be theoretically shown to converge to the right answer if one waits infinitely long, but these theoretical guarantees are worse than exhaustive search and therefore of minimal import.
. Some simulated annealing algorithms can be theoretically shown to converge to the right answer if one waits infinitely long, but these theoretical guarantees are worse than exhaustive search and therefore of minimal import.
- Tabu Search
- to prevent the search from repeating past mistakes, keep an explicit list of changes made recently and avoid changing one's mind.
- Genetic Algorithms
- Inspired by biological evolution. Rather than keeping 1 current solution, keep a population of solutions. Simulate mutation and sexual reproduction.
[edit] Approximation Algorithms
Determining the exact optimum value of an NP-complete optimization problem in polynomial time is not possible unless P=NP, but many such problems can be solved approximately in polynomial time. For example, the MAX-CUT problem (see above) can be approximated to within a factor of two by simply choosing a random cut! To see that this is a two-approximation, note that firstly, the optimum cut can cut at most all the edges, and secondly, every edge will be cut with probability 1/2, so on average half of the edges will be cut.
[edit] See also
[edit] References
- ↑ M. Agrawal, N. Kayal, and N. Saxena. "Primes is in P." Ann. Math. v. 160, pp. 781-793, 2004. http://www.cse.iitk.ac.in/users/manindra/algebra/primality_v6.pdf.
- ↑ Weisstein, Eric W. "AKS Primality Test." From MathWorld--A Wolfram Web Resource. http://mathworld.wolfram.com/AKSPrimalityTest.html
| |
Some content on this page may previously have appeared on Citizendium. |