Factor analysis

Contents |
Factor analysis is a statistical technique used to explain variability among observed random variables in terms of fewer unobserved random variables called factors. The observed variables are modeled as linear combinations of the factors, plus "error" terms. Factor analysis originated in psychometrics, and is used in social sciences, Marketing, product management, operations research, and other applied sciences that deal with large quantities of data.
[edit] Example
This oversimplified example should not be taken to be realistic.
Suppose a psychologist proposes a theory that there are two kinds of intelligence, "verbal intelligence" and "mathematical intelligence". Note that these are inherently unobservable. Evidence for the theory is sought in the examination scores of 1000 students in each of 10 different academic fields. If each student is chosen randomly from a large population, then the student's 10 scores are random variables. The psychologist's theory may say that, for each of the 10 subjects, the score averaged over the group of all students who share some common pair of values for verbal and mathematical "intelligences" is some constant times their level of verbal intelligence plus another constant times their level of mathematical intelligence, i.e., it is a linear combination of those two "factors". The numbers, for this particular subject, by which the two kinds of intelligence are multiplied to obtain the expected score, are posited by the theory to be the same for all intelligence level pairs, and are called "factor loadings" for this subject. For example, the theory may hold that the average student's aptitude in the field of amphibology is
- { 10 × the student's verbal intelligence } + { 6 × the student's mathematical intelligence }.
The numbers 10 and 6 are the factor loadings associated with amphibology. Other academic subjects may have different factor loadings.
Two students having identical degrees of verbal intelligence and identical degrees of mathematical intelligence may have different aptitudes in amphibology because individual aptitudes differ from average aptitudes. That difference is called the "error" — a statistical term that means the amount by which an individual differs from what is average for his or her levels of intelligence (see errors and residuals in statistics).
The observable data that go into factor analysis would be 10 scores of each of the 1000 students, a total of 10,000 numbers. The factor loadings and levels of the two kinds of intelligence of each student must be inferred from the data. Even the number of factors (two, in this example) must be inferred from the data.
[edit] Mathematical model of the same example
In the example above, for i = 1, ..., 1,000 the ith student's scores are
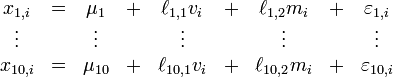
where
- xk,i is the ith student's score for the kth subject
- μk is the mean of the students' scores for the kth subject (assumed to be zero, for simplicity, in the example as described above, which would amount to a simple shift of the scale used)
- vi is the ith student's "verbal intelligence",
- mi is the ith student's "mathematical intelligence",
-
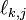 are the factor loadings for the kth subject, for j = 1, 2.
are the factor loadings for the kth subject, for j = 1, 2.
- εk,i is the difference between the ith student's score in the kth subject and the average score in the kth subject of all students whose levels of verbal and mathematical intelligence are the same as those of the ith student,
In matrix notation, we have
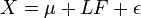
where
- X is a 10 × 1,000 matrix of observable random variables,
- μ is a 10 × 1 column vector of unobservable constants (in this case "constants" are quantities not differing from one individual student to the next; and "random variables" are those assigned to individual students; the randomness arises from the random way in which the students are chosen),
- L is a 10 × 2 matrix of factor loadings (unobservable constants),
- F is a 2 × 1,000 matrix of unobservable random variables,
- ε is a 10 × 1,000 matrix of unobservable random variables.
Observe that by doubling the scale on which "verbal intelligence"—the first component in each column of F—is measured, and simultaneously halving the factor loadings for verbal intelligence makes no difference to the model. Thus, no generality is lost by assuming that the standard deviation of verbal intelligence is 1. Likewise for mathematical intelligence. Moreover, for similar reasons, no generality is lost by assuming the two factors are uncorrelated with each other. (However, since any rotation of a solution is also a solution, this makes interpreting the factors difficult. See disadvantages below. In this particular example, if we do not know ex ante that the two types of intellegence are uncorrelated, then we can not interpret the two factors as the two different types of intellegence. Even if they are uncorrelated, we can not tell which factor corresponds to verbal intellegence and which corresponds to mathematical intellegence without an outside argument.) The "errors" ε are taken to be independent of each other. The variances of the "errors" associated with the 10 different subjects are not assumed to be equal.
The values of the loadings L, the averages μ, and the variances of the "errors" ε must be estimated given the observed data X. [How this is done is a subject that must get addressed in this article, which remains "under construction".]
[edit] Factor analysis in psychometrics
[edit] History
Charles Spearman pioneered the use of factor analysis in the field of psychology and is sometimes credited with the invention of factor analysis. He discovered that schoolchildren's scores on a wide variety of seemingly unrelated subjects were positively correlated, which led him to postulate that a general mental ability, or g, underlies and shapes human cognitive performance. His postulate now enjoys broad support in the field of intelligence research, where it is known as the g theory.
Raymond Cattell expanded on Spearman’s idea of a two-factor theory of intelligence after performing his own tests and factor analysis. He used a multi-factor theory to explain intelligence. Cattell’s theory addressed alternate factors in intellectual development, including motivation and psychology. Cattell also developed several mathematical methods for adjusting psychometric graphs, such as his "scree" test and similarity coefficients. His research lead to the development of his theory of fluid and crystallized intelligence, as well as his 16 Personality Factors theory of personality. Cattell was a strong advocate of factor analysis and psychometrics. He believed that all theory should be derived from research, which supports the continued use of empirical observation and objective testing to study human intelligence.
[edit] Applications in psychology
Factor analysis has been used in the study of human intelligence and human personality as a method for comparing the outcomes of (hopefully) objective tests and to construct matrices to define correlations between these outcomes, as well as finding the factors for these results. The field of psychology that measures human intelligence using quantitative testing in this way is known as psychometrics (psycho=mental, metrics=measurement).
[edit] Advantages
- Offers a much more objective method of testing traits such as intelligence in humans
- Allows for a satisfactory comparison between the results of intelligence tests
- Provides support for theories that would be difficult to prove otherwise
[edit] Disadvantages
- "...each orientation is equally acceptable mathematically. But different factorial theories proved to differ as much in terms of the orientations of factorial axes for a given solution as in terms of anything else, so that model fitting did not prove to be useful in distinguishing among theories." (Sternberg, 1977). This means all rotations represent different underlying processes, but all rotations are equally valid outcomes of standard factor analysis optimization. Therefore, it is impossible to pick the proper rotation using factor analysis alone.
- "[Raymond Cattell] believed that factor analysis was 'a tool that could be applied to the study of behavior and ... might yield results with an objectivity and reliability rivaling those of the physical sciences (Stills, p. 114).'" [1] In other words, one’s gathering of data would have to be perfect and unbiased, which will probably never happen.
- Interpreting factor analysis is based on using a “heuristic”, which is a solution that is "convenient even if not absolutely true" (Richard B. Darlington). More than one interpretation can be made of the same data factored the same way.
[edit] Factor analysis in marketing
The basic steps are:
- Identify the salient attributes consumers use to evaluate products in this category.
- Use quantitative marketing research techniques (such as surveys) to collect data from a sample of potential customers concerning their ratings of all the product attributes.
- Input the data into a statistical program and run the factor analysis procedure. The computer will yield a set of underlying attributes (or factors).
- Use these factors to construct perceptual maps and other product positioning devices.
[edit] Information collection
The data collection stage is usually done by marketing research professionals. Survey questions ask the respondent to rate a product sample or descriptions of product concepts on a range of attributes. Anywhere from five to twenty attributes are chosen. They could include things like: ease of use, weight, accuracy, durability, colourfulness, price, or size. The attributes chosen will vary depending on the product being studied. The same question is asked about all the products in the study. The data for multiple products is coded and input into a statistical program such as SPSS or SAS.
[edit] Analysis
The analysis will isolate the underlying factors that explain the data. Factor analysis is an interdependence technique. The complete set of interdependent relationships are examined. There is no specification of either dependent variables, independent variables, or causality. Factor analysis assumes that all the rating data on different attributes can be reduced down to a few important dimensions. This reduction is possible because the attributes are related. The rating given to any one attribute is partially the result of the influence of other attributes. The statistical algorithm deconstructs the rating (called a raw score) into its various components, and reconstructs the partial scores into underlying factor scores. The degree of correlation between the initial raw score and the final factor score is called a factor loading. There are two approaches to factor analysis: "principal components analysis" (the total variance in the data is considered); and "common factor analysis" (the common variance is considered).
Note that there are very important conceptual differences between the two approaches, an important one being that the common factor model involves a testable model whereas principal components does not. This is due to the fact that in the common factor model, unique variables are required to be uncorrelated, whereas residuals in principal components are correlated. Finally, components are not latent variables; they are linear combinations of the input variables, and thus determinate. Factors, on the other hand, are latent variables, which are indeterminate. If your goal is to fit the variances of input variables for the purpose of data reduction, you should carry out principal components analysis. If you want to build a testable model to explain the intercorrelations among input variables, you should carry out a factor analysis.
The use of principal components in a semantic space can vary somewhat because the components may only "predict" but not "map" to the vector space. This produces a statistical principal component use where the most salient words or themes represent the preferred basis.
[edit] Advantages
- both objective and subjective attributes can be used
- it is fairly easy to do, inexpensive, and accurate
- it is based on direct inputs from customers
- there is flexibility in naming and using dimensions
[edit] Disadvantages
- Usefulness depends on the researchers' ability to develop a complete and accurate set of product attributes - If important attributes are missed the value of the procedure is reduced accordingly.
- Naming of the factors can be difficult - multiple attributes can be highly correlated with no apparent reason.
- If the observed variables are completely unrelated, factor analysis is unable to produce a meaningful pattern (though the eigenvalues will highlight this: suggesting that each variable should be given a factor in its own right).
- If sets of observed variables are highly similar to each other but distinct from other items, Factor analysis will assign a factor them, even though this factor will essentially capture true variance of a single item.
[edit] References
- Abdi, H. "[2] (2003). Factor Rotations in Factor Analyses. In M. Lewis-Beck, A. Bryman, T. Futing (Eds): Encyclopedia for research methods for the social sciences. Thousand Oaks (CA): Sage. pp. 792-795.]".
- Abdi, H. "[3] ((2007). Multiple factor analysis. In N.J. Salkind (Ed.): Encyclopedia of Measurement and Statistics. Thousand Oaks (CA): Sage.".
- Abdi, H. "[4] ((2007). Multiple correspondence analysis. In N.J. Salkind (Ed.): Encyclopedia of Measurement and Statistics. Thousand Oaks (CA): Sage.".
- Charles Spearman. Retrieved July 22, 2004, from http://www.indiana.edu/~intell/spearman.shtml
- Exploratory Factor Analysis - A Book Manuscript by Tucker, L. & MacCallum R. (1993). Retrieved June 8, 2006, from: http://www.unc.edu/~rcm/book/factornew.htm
- Factor Analysis. (2004). Retrieved July 22, 2004, from http://comp9.psych.cornell.edu/Darlington/factor.htm
- Factor Analysis. Retrieved July 23, 2004, from http://www2.chass.ncsu.edu/garson/pa765/factor.htm
- Raymond Cattell. Retrieved July 22, 2004, from http://www.indiana.edu/~intell/rcattell.shtml
- Sternberg, R.J.(1990). The geographic metaphor. In R.J. Sternberg, Metaphors of mind: Conceptions of the nature of intelligence (pp.85-111). New York: Cambridge.
- Stills, D.L. (Ed.). (1989). International encyclopedia of the social sciences: Biographical supplement (Vol. 18). New York: Macmillan.
[edit] See also
- product positioning
- perceptual mapping
- marketing research
- product management
- list of marketing topics
- recommendation system
- Louis Thurstone
- The Mismeasure of Man
| |
Some content on this page may previously have appeared on Citizendium. |