Matrix
A matrix (plural "matrices") is a mathematical construct generally represented as a rectangular array of elements. These elements are usually numbers, but can be other matrices, and other mathematical structures. Matrices with real elements are called "real matrices", matrices with complex elements are called "complex matrices", and so on. Matrices with matrices as elements are called "partitioned matrices".
Among their other applications, matrices are fundamental to the study of linear algebra, since every linear transformation can be represented by a unique matrix, and every matrix represents a unique linear transformation.
Contents |
Dimensions and coordinates
A matrix with m rows and n columns is described as an m×n (pronounced "m by n") matrix, with the number of rows always coming first. When one dimension of a matrix is equal to 1 -- that is, in the case of a 1×n or m×1 matrix -- the matrix is a vector. A matrix with one row is a row vector; a matrix with one column is a column vector.
If the m×n matrix is named A, individual entries are named 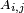 , where
, where 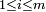 and
and 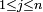 ; again, the row coordinate comes first. For example, suppose M is a 3×4 matrix:
; again, the row coordinate comes first. For example, suppose M is a 3×4 matrix:
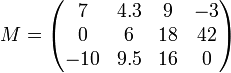
Now we can say that 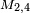 = 42: the element in the second row and the fourth column, counting from the top left.
= 42: the element in the second row and the fourth column, counting from the top left.
Notational conventions vary; the comma in the subscript is sometimes omitted, so the same entry would be named 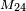 ; of course, this notation is only practical when the matrix in question is smaller than 10×10. A superscript-subscript notation is sometimes used, where the row coordinate appears as a superscript and the column coordinate appears as a subscript, thus:
; of course, this notation is only practical when the matrix in question is smaller than 10×10. A superscript-subscript notation is sometimes used, where the row coordinate appears as a superscript and the column coordinate appears as a subscript, thus: 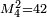 . While upper-case letters are almost universally used for matrices themselves, some texts maintain the upper-case letter for the individual elements (e.g. ) while others use lower-case (e.g.
. While upper-case letters are almost universally used for matrices themselves, some texts maintain the upper-case letter for the individual elements (e.g. ) while others use lower-case (e.g. 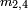 ). Finally, in typesetting the matrix itself, some texts place large parentheses around the elements while others use large square brackets.
). Finally, in typesetting the matrix itself, some texts place large parentheses around the elements while others use large square brackets.
Operations
Several operations are defined for matrices.
Matrix addition
Two matrices may be added if and only if they have identical dimensions. The sum of the matrices is simply the matrix composed of the sums of the entries. That is, if A and B are m×n matrices, then A + B is an m×n matrix such that
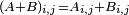 for all i, j with and
for all i, j with and
For example:
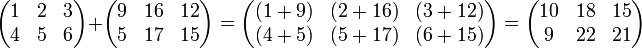
Just as with numeric addition, matrix addition is commutative:
- A + B = B + A
and associative:
- A + (B + C) = (A + B) + C
Scalar multiplication
Any scalar may be multiplied by any matrix. To obtain the resultant matrix, multiply each entry of the original matrix by the scalar. That is, if c is a scalar and A is an m×n matrix, then cA is an m×n matrix such that
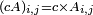
For example:
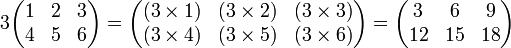
Matrix multiplication
Two matrices A and B may be multiplied if A has as many columns as B has rows. (Otherwise, they are said to be incompatible and their product is undefined.) That is, an m×n matrix may be multiplied by an n×p matrix. Then the resultant matrix AB is m×p and the (i,j)th entry of AB is the vector dot product of the ith row of A and the jth column of B. Formally:
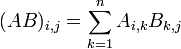
For example:
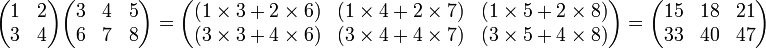
Even if AB is defined, BA may not be. If both matrices are defined, they may have different dimensions. Even if they have the same dimensions, they may not be equal. Thus, matrix multiplication is clearly not commutative. It is, however, associative:
- A(BC) = (AB)C
and left- and right-distributive:
- A(B + C) = AB + AC and (A + B)C = AC + BC
so long as all the relevant products are defined.
Transposition
Given an m×n matrix A, its transpose (denoted 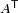 ) is an n×m matrix where each row in A is a column in and vice versa. That is:
) is an n×m matrix where each row in A is a column in and vice versa. That is:
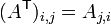
For example:
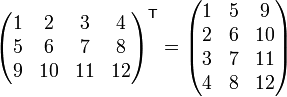
Note that the transpose operation is its own inverse; for all matrices A, 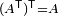 .
.
Special matrices
Certain types of matrices prove useful in different contexts.
Square matrices
A square matrix, as the term implies, is any matrix of dimension n×n -- that is, with the same number of rows as columns. Two n×n matrices may always be multiplied, and their product is another n×n matrix.
Identity matrix
We denote by 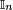 the multiplicative identity for matrix multiplication; that is, the matrix such that
the multiplicative identity for matrix multiplication; that is, the matrix such that
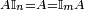 for any m×n matrix A.
for any m×n matrix A.
takes the form of a n×n square matrix with the number 1 down its main diagonal, starting from element (1, 1), and the number 0 everywhere else. So
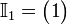 ,
, 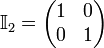 ,
, 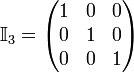 , ...
, ...
In general, the n subscript is included only if necessary; if the size of the identity matrix can be deduced from context, we omit the subscript. For example, we would most likely say:
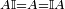
since only one identity matrix is dimensionally compatible for multiplication.
Zero matrix
The additive identity under matrix addition is known as a zero matrix, and denoted 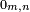 for an m×n matrix. Its entries are all zeroes, so (for example)
for an m×n matrix. Its entries are all zeroes, so (for example)
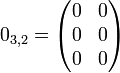
It is evident that for any m×n matrix A,
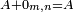
It is also clear that the product of any matrix with a zero matrix is another zero matrix, which may or may not have the same dimensions. As with the identity matrix, the subscript is omitted if the context admits only one zero matrix. In this example, any other zero matrix could not be added to A, so the subscript is redundant and we could say
- A + 0 = A
Invertible matrix
Some, but not all, matrices have a multiplicative inverse. That is, for a matrix A, there may exist a matrix 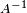 such that
such that
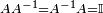
Only square matrices may be inverted. Furthermore, if the determinant of a square matrix is 0, it is singular -- that is, not invertible.
Some square matrices without inverses may have matrix "pseudoinverses", which have properties extending the concept inverses.
Symmetric matrix
A symmetric matrix is equal to its transpose. It must therefore be a square matrix, with values reflected across the main diagonal. That is, if A is an n×n matrix, A is symmetric if and only if
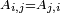 for all
for all 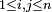
For example:
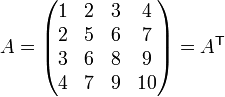
Antisymmetric matrix
An antisymmetric or skew-symmetric matrix is the additive inverse of its transpose. It must also therefore be a square matrix. If A is an n×n matrix, A is antisymmetric if and only if
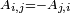 for all
for all
Therefore, it is a requirement that all entries on the main diagonal of an antisymmetric matrix equal zero. For example:
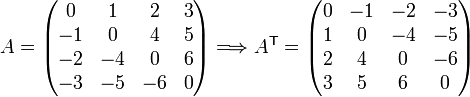
Diagonal matrix
A matrix that has zeros everywhere other than the main (upper left to lower right) diagonal is a Diagonal matrix.
Example:
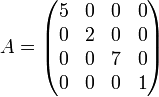
Diagonal matrices are especially easy to invert or operate with.
Scalar matrix
A diagonal matrix all of whose diagonal entries are equal is a Scalar matrix. Scalar matrices are so called because their multiplicative action on other matrices is the same as multiplication by a scalar element. A scalar matrix is just a scalar multiple of the identity matrix.
Example:
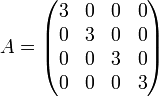
Triangular matrix
A matrix that has only zeros above (below) the main diagonal is called a lower (upper) triangular matrix. Examples:
Upper triangular:
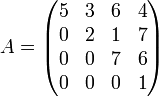
Lower triangular:
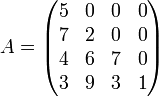
Triangular matrices are especially easy to invert or operate with.
Orthogonal matrix
A matrix is Orthogonal if the transpose of the matrix is equal to its inverse.
Hermitian Matrix
A Hermitian matrix (or self-adjoint matrix) is one which is equal to its Hermitian adjoint (also known as its conjugate transpose). That is to say that every entry in the transposed matrix is replaced by its complex conjugate:
 ,
,
or in matrix notation:
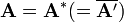
Idempotent Matrix
A matrix is Idempotent if it is equal to its square.
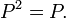
An idempotent matrix P has eigenvalues 0 or 1 and has a basis of eigenvectors: it is diagonalisable since its minimal polynomial polynomial X2-X has no repeated roots. The kernel and image of P are complements: they form an internal direct sum.
Sparse Matrix
If a matrix has enough zero elements that one can take advantage of the fact, a matrix is called a "Sparse Matrix". Triangular matrices and Diagonal matrices are examples of sparse matrices
Applications
Systems of linear equations
Matrix techniques are often used to solve systems of equations in several variables, because any system of linear equations may be represented in matrix form. For example, the system
- a1x + b1y + c1z = d1
- a2x + b2y + c2z = d2
- a3x + b3y + c3z = d3
is equivalent to the equation
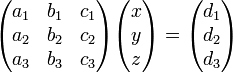
where the unknowns are entirely within the second matrix. Then, if the first matrix is invertible, x, y, and z can be recovered:
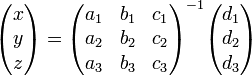
Solving linear systems is extensively in Physics, Mechanics, and many other fields.
Linear transformations
If f is a linear mapping from 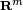 to
to 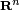 , then there exists a unique m×n matrix F such that for any vector x in ,
, then there exists a unique m×n matrix F such that for any vector x in ,
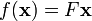
These transformations have extensive use in Computer Graphics, and in mechanics.
Least Squares problems
Surveying problems with redundant (and not quite consistant) measurements were first studied by Gauss and he developed "Least Squares" to find solutions that were "close" to the systems the data described. The exact sense of "close" was that the solution had the lowest possible sum of the squares of the differences between the data at hand and the solution given. He pioneered the use of matrix "Normal Equations" for the problem, although today matrix "Orthogonalization" methods such as QR factorization are more commonly used.
Finite Element methods
Breaking an object into a mesh of points, and computing the interactions of those points, is used in a number of Engineering fields to model materials. Various matrix methods are used to deal with the problem.
| |
Some content on this page may previously have appeared on Citizendium. |